前言
这段时间在学习正则,学完总想拿来实践一下,转头想了想,干起了老本行——爬虫,虽然之前写爬虫的时候也用到了正则,但是都是知其然不知其所以然,也好久没有过python写代码了,随便写了写脚本,之后也会写一些渗透用的脚本(poc或者exp),这些都会放到杂项分类里面。
程序目标
思来想去,也没啥想爬取的内容,想起每次用hexo把博客推到远端,得要打开客户端看一下推成功了没,就像爬取一下自己博客的信息,只要用来练练手,就是没事做,闲得慌。
程序代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
| import requests
import re
import optparse
import urllib
url = "https://bmoos.github.io"
agent = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'}
def init():
r = requests.get(url,headers = agent)
pattern_url_name = re.compile(r'<a href="(.*?)" class="post-title-link" itemprop="url">(.*?)</a>')
pattern_lasttime = re.compile(r'<time title="创建时间:(.*?)"')
pattern_word = re.compile(r'<span>([\d.\w]*)</span>')
pattern_page = re.compile(r'<a class="page-number" href="(.*?)">')
passage = re.findall(pattern_url_name,r.text)
lasttime = re.findall(pattern_lasttime,r.text)
word = re.findall(pattern_word,r.text)
page = re.findall(pattern_page,r.text)
for i in page:
url_page = url + i
req = requests.get(url_page,headers = agent)
passage += re.findall(pattern_url_name,req.text)
lasttime += re.findall(pattern_lasttime,req.text)
word += re.findall(pattern_word,req.text)
all_information = []
for i in range(len(passage)):
passage_information = []
passage_information.append(passage[i][0])
passage_information.append(passage[i][1])
passage_information.append(lasttime[i])
passage_information.append(word[i])
all_information.append(passage_information)
return all_information
def print_list():
table = init()
print('--------------------------------------------------')
print('passage_name/create_time/word_number')
print('--------------------------------------------------')
for i in range(len(table)):
print(table[i][1]+'/'+table[i][2]+'/'+table[i][3])
print('--------------------------------------------------')
def print_passage(name):
table = init()
for i in range(len(table)):
if name == table[i][1]:
urls = url + urllib.parse.unquote(table[i][0])
print('文章地址:'+urls)
return
print('文章名出错')
def main():
parser = optparse.OptionParser("%prog " + "-l or -p <passage>")
parser.add_option('-l', action = 'store_true', dest = 'list', help = 'all passage information')
parser.add_option('-p', dest = 'passage_name', type = 'string', help = 'passage content')
(options, args) = parser.parse_args()
if options.list and options.passage_name == None:
print_list()
if options.passage_name and options.list == None:
print_passage(options.passage_name)
if __name__ == '__main__':
main()
|
用法:在命令行使用,有两个参数,一个是-l用来查看所有的博客文章:
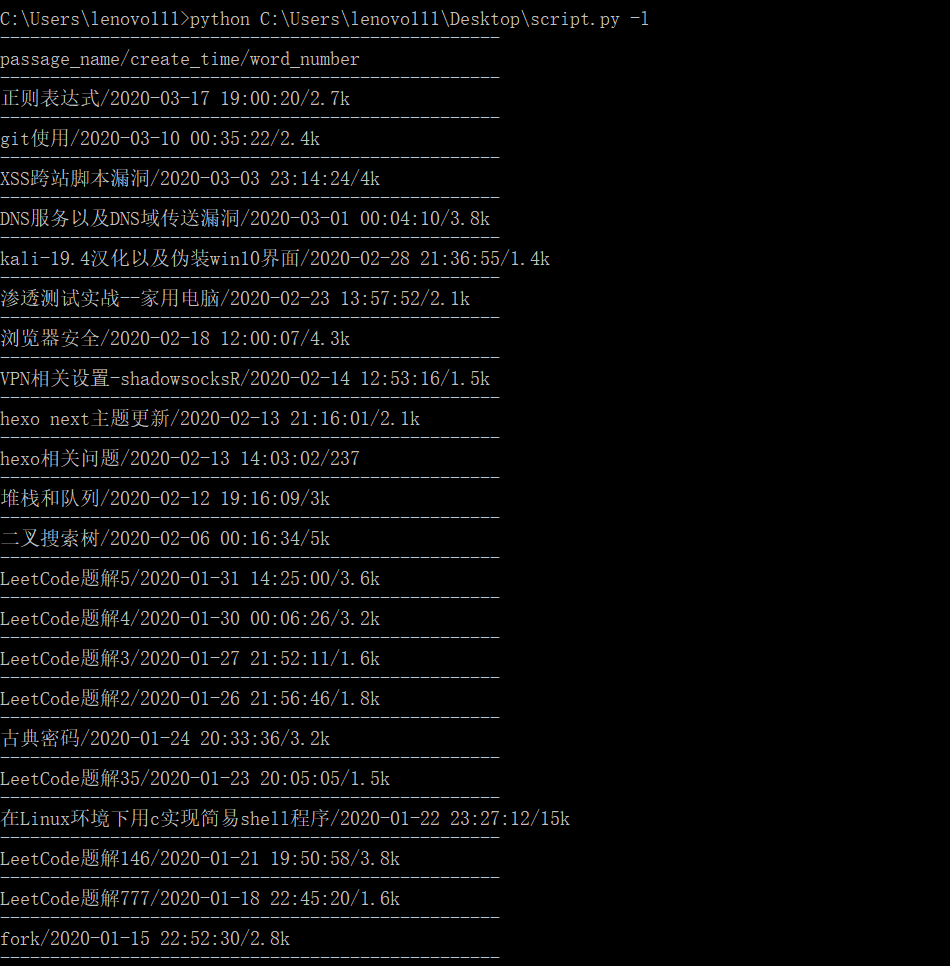
一个是-p后跟博客文章名,可以返回博客文章链接(PS:本来是想返回博客内容的,但是看到博客内容不是连续的文本,有很多标签分割,正则不可能,而且博客也有图片,最后实现和自己想的差很多,就只能返回博客文章地址,之后更新的时候或许会加入其他功能,之后在想)
