正则表达式
前言
正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为”元字符”)。
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
学习正则可以提高效率,而且现在大多语言都支持正则,之前因为觉得正则太复杂而放弃,现在有了大把时间可以重新学习一下。。。
注意:本文只是对正则入门级操作,复杂多样的正则不涉及(PS:太难了QAQ)。
正则的普通用法
正则表达式描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
构造正则表达式的方法和创建数学表达式的方法一样。也就是用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式。正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为”元字符”)组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
(以上引用菜鸟教程正则表达式)
简单来说正则表达式就是就一个用一些既定的规则表示要查找的子串格式,逻辑上说和正常生活中查找字符串逻辑差不多(用一些字符串的特征去查找),这是我的理解,对我来说正则表达式复杂多样,我只要会使用简单的正则,会读懂复杂正则表达式就足够了。
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为”元字符”)组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
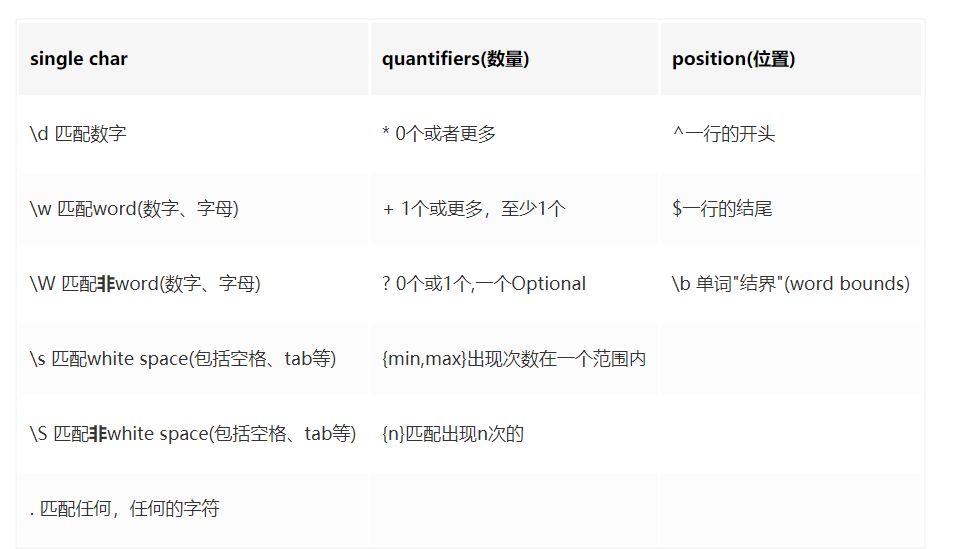
(注意:遇到特殊字符,比如:( ) / . * + { } ? $ ^等可以用’ \ ‘进行转义)
根据上图其实已经掌握了基本的正则表达式,现在举个例子
This is somthing
is about
a blah
words
sequence of words
Hello and
GoodBye and
Go gogo!
在其中找到长度为5的单词 /\b\w{5}\b/g
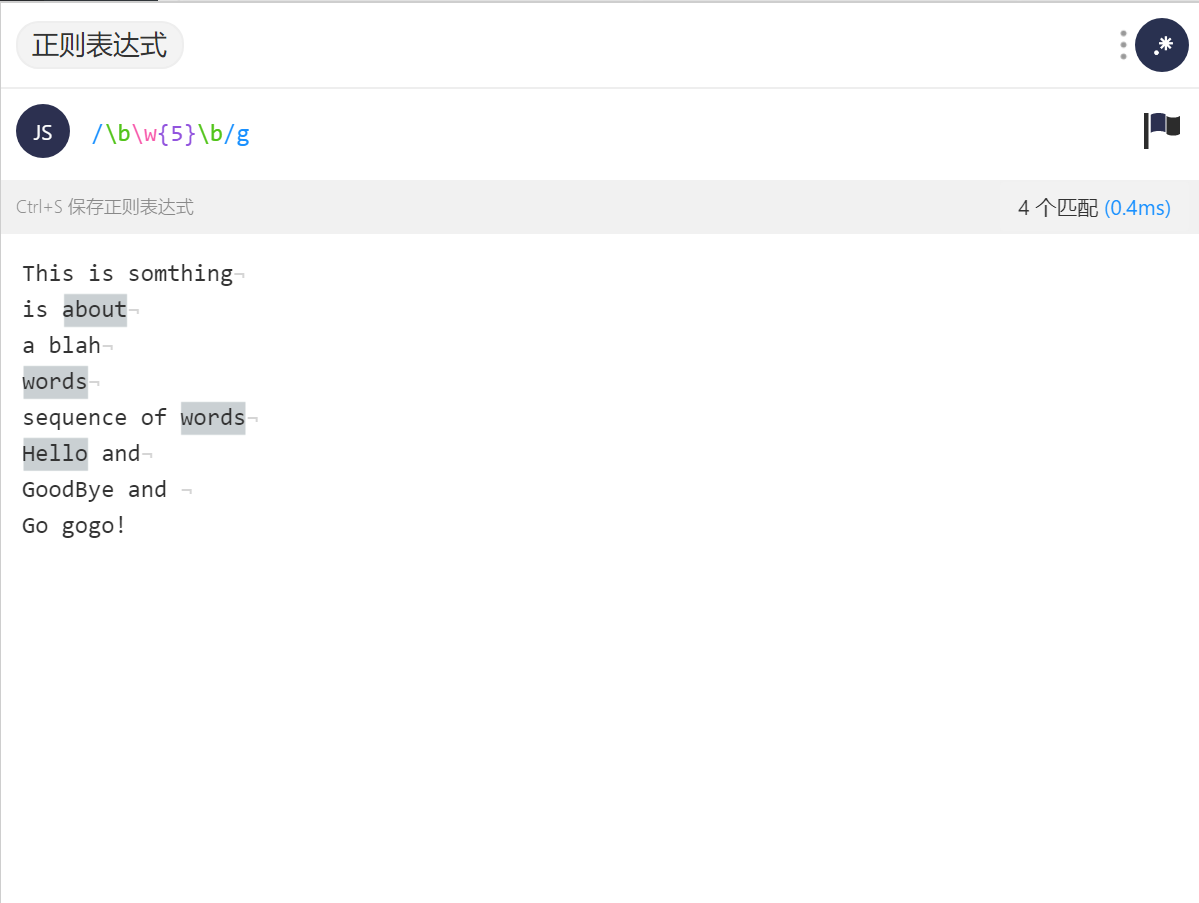
注意:* +限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
例如:
<html>javascript>正则表达式
/<.*>/和/<.+>/会匹配到<html>javascript>而如果想要匹配
<html>,可以用到/<.*?>/或/<.+?>/
正则分类符
之前所说的是普通字符,现在来考虑分类符
eg:要查找电话号码,已知有如下三种格式的电话号码
134-3737-4399
134.3737.4399
(029)8288-4399
当然我们可以分别用/\d{3}-\d{4}-\d{4}/ /\d{3}.\d{4}.\d{4}/``/\(\d{3}\)\d{4}-\d{4}/三个正则表达式来查找
但是有没有通用的正则表达式呢
当然,可以使用[]分类符
bmoos bmoo$ bmoo3
可以用
/bmoo[s$3]/来查找
那么[]的意思就是在该位置上的字符是[]里的任意一个字符,可以理解为”或”
那上述电话号码可以用到通用的正则表达式/\(?\d{3}[-.)]\d{4}[-.]\d{4}/
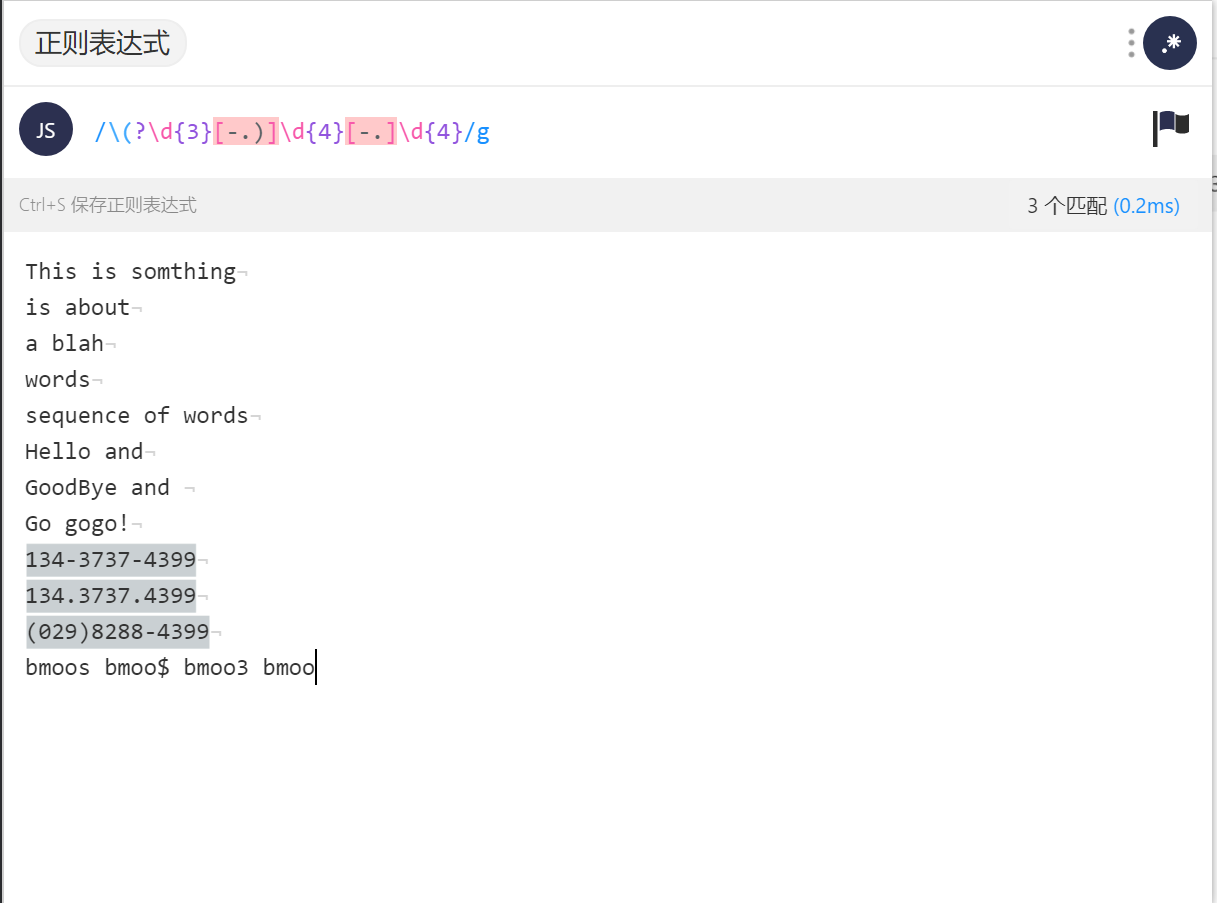
刚才介绍了最简单和基本的功能,但是有些特殊的地方需要注意
- -连接符是第一个字符时
比如[-.]的含义是连字符-或者点符.。 但是,如果当连字符不是第一个字符时,比如[a-z],这就表示是从字母a到字符z。
[]中的^
^在之前介绍中,是表示一行开头,但是在[]中,有着不同的含义。 [ab] 表示a或者b ,[^ab]表示啥都行,只要不是a或b,相当于取反
除了可以用[]表达或逻辑外,还可以用一种方式表达(a|b)
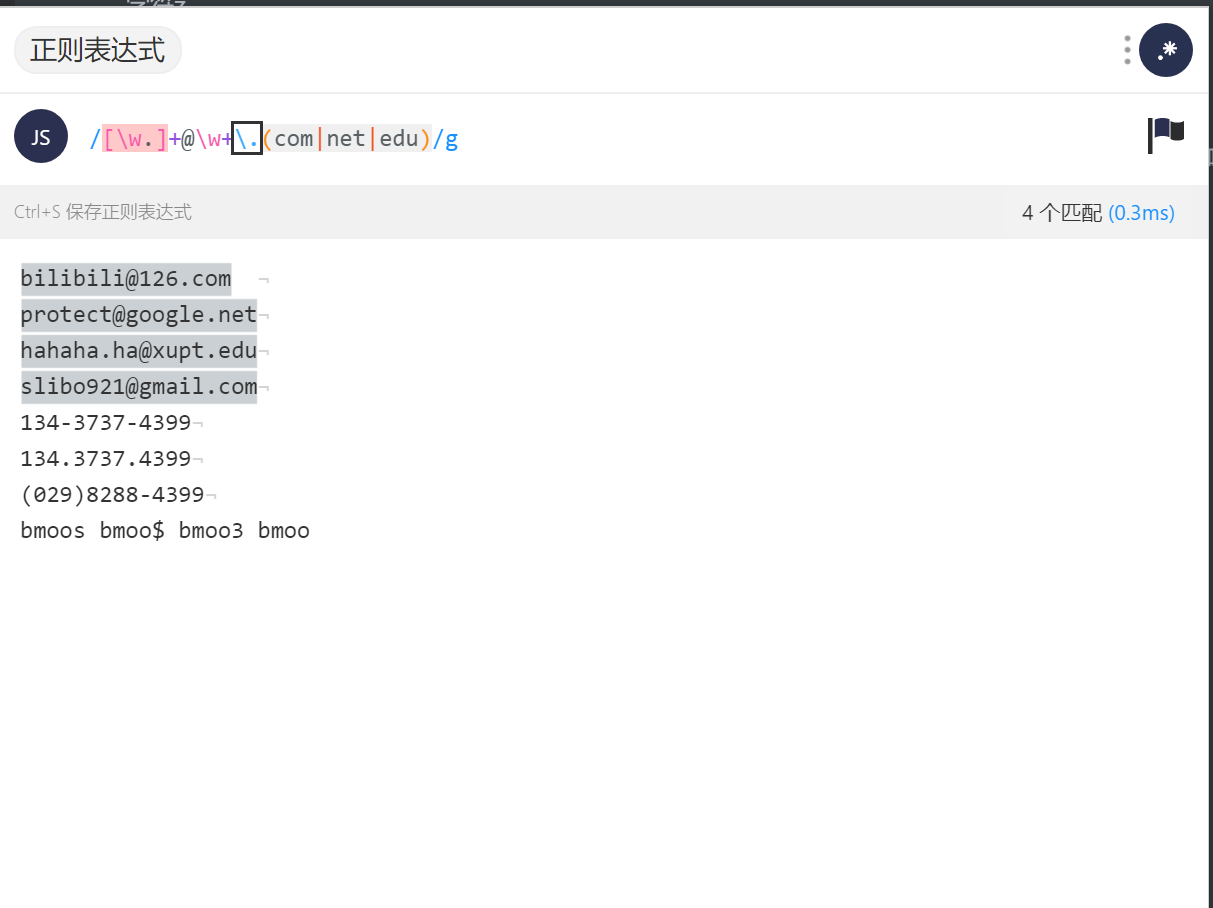
eg:写一个邮箱的正则表达式:
bilibili@126.com
protect@google.net
hahaha.ha@xupt.edu
slibo921@gmail.com
那么可以用正则表达式:/[\w.]+@\w+\.(com|net|edu)/
python中的正则
在python中正则主要使用re模块
re模块中有以下主要函数:
re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:
re.match(pattern, string, flags)
re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags)
检索和替换
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0, flags)
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- flags : 编译时用的匹配模式,数字形式。
前三个为必选参数,后两个为可选参数。
compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
语法格式为:
re.compile(pattern[, flags])
findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
语法格式为:
re.findall(pattern, string, flags)
re.finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
re.finditer(pattern, string, flags)
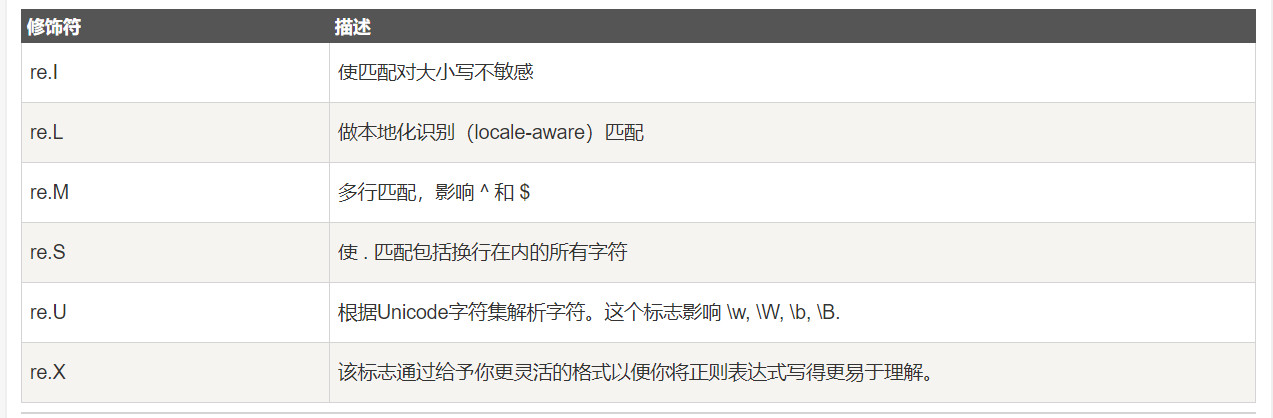
可选修饰符flags
参考文章
https://juejin.im/post/5b5db5b8e51d4519155720d2#heading-6